Research Note
Table of contents
Tries to findout fundamental ways (2024)
change the ways
- Redefine the assessment
- universal framework needed for CV, LM, and so on
- need more mathematical approach
might we need to interact the data manifold. (2024. 12.)
sRFL (Dec. 2023)
sRFL - Introduction
sRFL is my works based on NeurIPS 2023 Machine Unlearning Challenge’s dataset (celebrities face dataset), It seems that the following methods achieved huge accuracy decoupling between retain and forget dataset in training, seams that it has a chance to achieve the machine unlearning.
I focused on the decoupling in the logit spaces, using teacher-student framework.
- sRFL (simple Rolling in Forget Logits)
sRFL - pseudo code
1. Copy a model from original trained model
teacher_model <- copy.deepcopy(model)
teacher_model.eval() // teacher model will not be trained
2. Freeze layers of model except for first two backbones (feature extracting)
3-1. Loop : Generate logits by teacher model
for data in datasets (retain + forget dataset):
retain_data, forget_data <- data
pseudo_forget_logits <- teacher_model(forget_data)
pseudo_retain_logits <- teacher_model(retain_data)
3-2. Roll only the pseudo_forget_logits (same mechanism in torch.roll with random roll steps in [-1,1])
rolled_pseudo_logits <- roll(pseudo_forget_logits)
3-3. Minimize KL-divergence between rolled_pseudo_logits and model’s output (from forget data), and use cosine similarity be a regularization and use retain_loss (KL-divergence between pseudo-label(not-rolled) and model outputs about retain dataset)
forget_outputs <- model(forget_data)
retain_outputs <- model(retain_data)
forget_loss <- KLDiv(rolled_pseudo_logits, forget_outputs) \
- cosine_similarity(rolled_pseudo_logits, forget_outputs)\
+ KLDiv(pseudo_retain_logits, retain_outputs)
3-4. backward propagation by forget_loss
forget_loss.backward()
End of Loop.
sRFL - conclusion
simple Rolling in Forget Logits (sRFL) is a simple way of disturbing the forget label in finetuning framework.
The following is about train accuracy about CIFAR-10
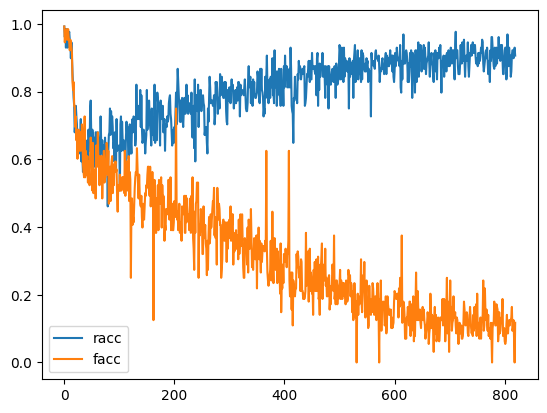
In the figure above, facc stands for accuracy of forgetting dataset, racc stands for accuracy of retain dataset.
While it achieved high decoupling, there’s a huge claim about their metrics and evaluation. Even though the competition is completed with some argues, the main idea of machine unlearning is quite crucial in privacy and robustness of the ml-based services. In the future, I will progress my works.